
Pangrams are sentences that contain every character in a writing system. The pangram most familiar to English-speakers is the quick brown fox jumps over the lazy dog - every letter of the alphabet occurs at least one time. Pangrams usually appear in typography; when you want to show off a new font succinctly, you can write out a pangram. However, I think pangrams are interesting for another reason: they show how the world’s writing systems differ from one another. In this blog post, I’m going to try and create pangrams in some of the world’s major writing systems: Chinese, Devanagari, Latin, Korean, Arabic and others. In the process I’ll explain how each system works, its origins, and its merits and limitations. In the end, you’ll have a much greater appreciation of the world’s writing systems.
Introduction
The basic building blocks of writing systems are called graphemes - these are the bits and pieces like T and ल and ش that get combined together to form words and sentences. The purpose of writing is to record speech, so there will always be a relationship between graphemes and sounds. Similarly, the fundamental building blocks of a language are called phonemes and are transcribed with the International Phonetic Alphabet. The IPA representation of the English word bee is /bi/ (linguists use slashes to indicate IPA transcriptions) and contains two phonenes: the consonant /b/ and the vowel /i/ despite being written with three letters.
People have invented hundreds of writing systems: they differ hugely in appearance, writing direction, and their pragmatic applications (here’s an application that organizes some of this chaos). However, all of this diversity can be reduced to a few basic categories:
-
Alphabets have letters that correspond to one vowel or consonant sound. English and Cyrillic (Кириллица) are alphabets. When you combine a consonant letter like k with a vowel letter like i you get a syllable: ki. Not all letters correspond directly to sounds: sh is a digraph that represents the phoneme /ʃ/, whereas x is a single letter that often represents two phonemes: /ks/. Although the alphabet is the writing system most familiar to Westerners, it’s probably the least natural: the alphabet has only been invented once in all of human history.
-
Syllabaries have characters that correspond to entire syllables. For instance, the Japanese word おとこ (man) has the following syllables: お = o, と = to, and こ = ko. We call languages syllabaries even when they contain small alphabetic components: Japanese has a character ん which corresponds to n. There are no pure syllabaries in the world, though some come close. Often when a new writing system is created from scratch, it’s a syllabary.
-
Abjabs have letters that correspond to one consonant phoneme, with optional diacritics to disambiguate vowels. For instance, the Arabic word شكرا (thanks) is pronounced shukran even though it’s written as shkra (you read it from right to left). Context lets Arabic speakers understand the appropriate vowel - also, it helps that Arabic dialects only have 3-5 vowels, whereas American English has more than 15. Try reading the following sentence and you’ll get a feel for the logic of written Arabic: Arbc hs n ntrstng wrtng systm.
-
Abugidas (or alpha-syllabaries) have base syllables. The vowels of these base syllables can then be modified with diacritics. For instance, you can modify the Devanagari syllable ल (la) in several ways: ले = le, लु = lu, ली = lee, etc. just by adding diacritics above, below, or next to the character. Devanagari also has a special killer stroke (virama in Sanskrit) that cancels out the inherent vowel.
-
Logographies have characters that correspond to entire words or morphemes. They evolved from pictograms. In a pictographic system, the moon might be represented by a crescent and the sun might be a disk. Some of the earliest writing systems - like Ancient Egyptian and Mayan Hieroglyphics - are pictographic systems. But pictograms aren’t relics of the past: emoji’s are a specific type of pictogram 😃 (The first documented emoji was in Dante’s Purgatorio). Picrograms are frequently included in other writing systems. When pictogram drawings become more abstract, you get logograms. The characters in logographic systems prioritize words over pronunciations, so 由于 (because of) and 鱿鱼 (squid) are written very differently but have exactly the same pronunciation: yóuyú.
In the next few sections, I’ll dissect examples of each of these writing systems, discussing how they work and compare to one another.
Alphabet: Korean Hangul (한글)
Hangul is the system used to write Korean. Hangul is an alphabet like English because there are letters that correspond to individual phonemes: ㅁ is /m/, ㄴ is /n/, etc. There are also sounds in Korean that have no equivalent in English: ㅈ is /tɕ/, ㅃ is /p͈/, and lots of others.
Unlike English, Korean letters get packed together into syllable “blocks”: add together ㄱ /k/, ㅣ /i/, and ㅁ /m/ and you get 김 /kim/. Tack on another syllable and you get 김치 - kimchi. These blocks superficially resemble Chinese, which makes sense, because the Korean language was written with Chinese logograms until it was replaced by Hangul, which was invented by Sejong the Great in the fifteenth century.
However, there’s a small hitch. Because Korean characters are all squeezed into super-convenient syllable blocks, they get warped slightly depending on their location in the block. The letter ㄱ is different when it’s in the syllable 길 (gil, road), 굴 (gool, oyster), and 궐 (gwol, palace):

These different “surface forms” of an “underlying” grapheme are called allographs. English has them too: there are MAJUSCULE (capital) and miniscule (lower-case) forms for each letter. English allographs can differ quite a bit: b and B don’t look particularly similar (where did the extra hoop on the capitalized form come from?) - Korean is much simpler by comparison.
However, Korean runs into trouble when you try to print it. Imagine that you’re a printer in the fifteenth century - you have to carve blocks out of wood or metal in the shape of letters, line them up into pages, and dip them in ink before pressing them onto paper. An English printer needs 26 * 2 = 52 letters. But because Korean allographs mutate subtly, you end up needing an individual block for every syllable in the language - and there are hundreds!
The syllable situation isn’t too bad for Korean, which has several hundred possible syllables (syllables are limited to CVC - consonant vowel consonant), but English is CCCVCCCC, so the number of possibilities is in the hundreds of thousands! I like the fact that Korean syllables are revealed by its script - you can do the same with Eng.lish by ad.ding per.i.ods, but it looks ug.ly.
But you’re not required to package Korean letters into syllable blocks. Often when a writing system invented for one language is borrowed into another, modifications are made that allow it to be more generally applicable to all languages (more on that in the Chinese (漢字) section). When Hangul was used to write the Indonesian language Cia-Cia the syllable-block structure was borrowed too, but you could imagine a scenario where Hangul was used to write a language that has really big syllables - like English. The single-syllable word sixths /sɪkθs/ simply has too many sounds to cram into a Korean-style syllable block, but you could write it out like this: ㅅㅣㄱㅈㅅ.
Keeping all of this in mind (and overlooking the problem of allographs), it’s easy to create a pangram that contains all the Hangul letters:
밤새 컴퓨터로 요약을 해치우면 좋겠다
This pangram is pronounced BamSae KumPyooTuhRo YoYakEul HaeChiWooMyun JotGetDa and means I’d love to blaze through the summary with the computer overnight.
For a typographer creating a new font, the flexibility of Korean letters might be a stumbling block. But for a language learner using paper-and-pencil, this flexibility doesn’t cause much difficulty. In fact, Korean is one of the easiest writing systems to learn. It’s made even easier, perhaps, because Korean is a special kind of writing system called a featural system. Hangul letters are meant to mirror the ways in which they’re produced: for instance, your lips purse shut when making an m sound, and this is reflected in the shape of the character ㅁ.
Syllabary: Japanese Hiragana (ひらがな)
Japanese is written with several different scripts, all used in combination and in the same documents. It makes use of Chinese characters (mostly for nouns, verb stems, and proper names), Latin letters (Romaji) for some foreign words, and two different syllabaries (kana) systems: Katakana (カタカナ) and Hiragana (ひらがな) - the former is used for loanwords and sometimes for emphasis (similar to bold), and the latter is mostly used for verb inflections and other grammatical purposes.
Technically you could write all of Japanese with just kana. However, Japanese insists on using all of its writing systems, even while tacitly admitting the complexity of its Chinese characters: small hiragana characters called furigana are sometimes even written next to obscure Chinese characters or in children’s books to aid comprehension:
Because hiragana is a syllabary, every character represents a single syllable - ひ = hi, ら = ra, が = ga, な = na. At first glance, this seems incredibly restrictive - how could you ever write all the syllables of a language? There are just too many - think of syllables as diverse as /skritʃd/ “screeched”, /kælp/ “clap”, and /strɛŋθ/ “strength.” As mentioned above, not all languages have the same syllable structure: English is CCCVCCCC, whereas Japanese is only CVN (N being a nasal consonant, which in Japanese is ん).
Japanese syllables can be “open” (CV) like ら ra, “closed” (CVN) like らん, or a single vowel like あ a. Initial consonants can also be palatalized: CjV, CjVN. Additionally, all the vowels can be long or short.
Because there are only 14 consonants, 5 vowels, 2 vowel lengths, one type of palatal, and one ん, there are 14 * 5 * 2 * 2 * 2 = 560 possible syllables in Japanese. This is a lot. Japanese deals with this by adding some hacks to bring the number of characters down significantly:
Hacks
Apart from its small alphabetic hack ん, Japanese has some other ways that prevent the burden of having a distinct character for every syllable.1
Long vowels in a syllable are indicated by adding an extra vowel after the syllable. For instance, か is /ka/ and あ is /a/ – かあ is /ka:/.
Consonants can become palatalized when you add a small ゃ after them (compare this to the large や, /ja/). For instance, き is /ki/ but きゃ is /kʲa/. These are called yōon and there are over seventy possible yōon combinations in Japanese.
A small っ (compare to the large つ, /t͡sɯ/) is called sokuon and indicates gemination (doubling) of a consonant: the two-syllable word ちょっと /t͡ɕotto/ uses sokuon and yōon.
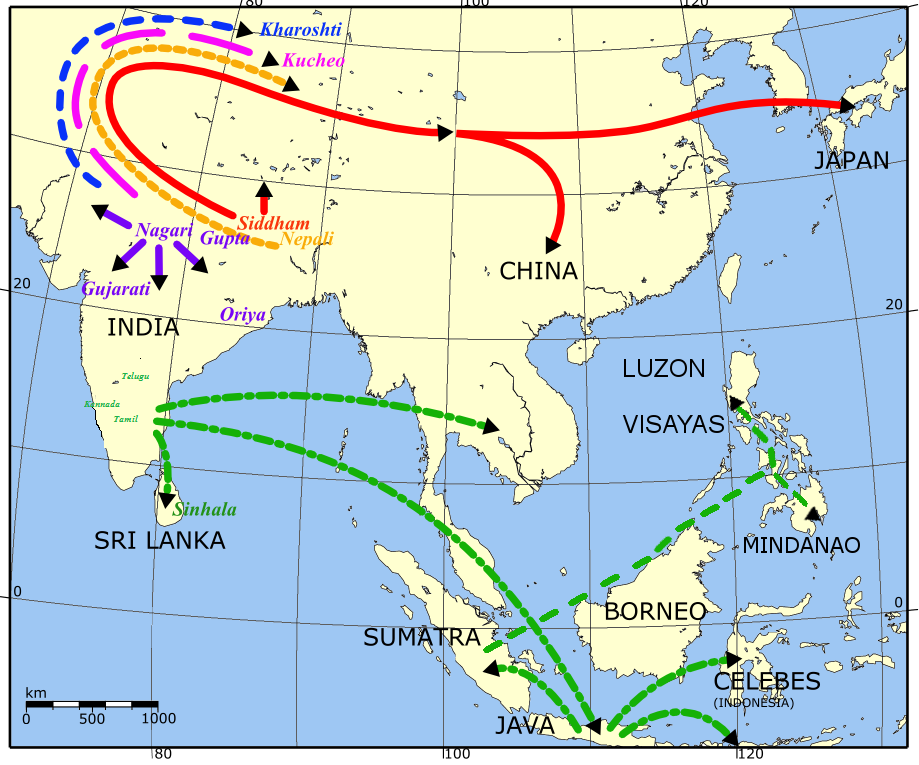
Diacritics are used to alter the voicing of certain syllables. For instance, か is the character for /ka/, but if you add the ゛ diacritic you get が, which is /ga/. In this way, hiragana behaves in a similar fashion to Devanagari, an abugida, where all syllables have base forms that are modified by diacritics (more on that in the Devanagari (देवनागरी) section). And this makes sense, because hiragana is probably influenced by Siddham, a Brahmic script (in the same family as Devanagari) that was brought to Japan from India by Buddhist priests.
A Historical Aside
At the beginning of the 4th century CE, Indian culture was entering into East Asia. Ruled by the Gupta Empire, Indian civilization was experiencing a golden age. This legacy includes the concept of zero, round earth theory, the base-10 numeral system, chess, the Kama Sutra, and an enormous body of Sanskrit literature. These creations were just too good to keep secret, and they quickly spread around the world.
A snapshot of this period of cultural transmission is captured by the Dunhuang manuscripts. These manuscripts were discovered in Western China in the early 20th century are are a treasure-trove of religious literature. Although they’re mostly Buddhist texts, there are also Nestorian Christian, Daoist, and Manichaean manuscripts. Collected from the 4th to 11th centuries, these texts are written in Chinese, Sogdian (image below), Hebrew, Old Uyghur, Khotanese, and Sanskrit.
Sanskrit texts written in the Siddham abugida made a large impact on Buddhism in China. But these texts influenced Japan to an even greater extent. One of the individuals influenced by the Silk Road transmission of Buddhism was Kukai, a Shingon priest who lived in the 8th century.

Kukai’s Dream
Kukai was born and educated in Japan. He pursued a Buddhist education, but felt alientated by the ritsuryo system that regulated the activity of priests and religious doctrine. Deciding to live outside this system, he became an ascetic. After wandering the countryside and searching for meaning, Kukai had a dream. In his dream a man revealed to him that the Mahavairocana Tantra contained the meaning that he was searching for. Although he was able to eventually obtain a copy of the text, it was written in Sanskrit using the Siddham abugida, and Kukai was unable to make sense of the document.
In order to understand the text, Kukai traveled to China to learn Sanskrit. On his return to Japan several years later, he brought with him the Siddham abugida. Kukai decided that Japanese should be written with a phonetic system instead of Chinese characters. Japanese folklore says that Kukai invented kana under the influence of Siddham to achieve this goal.
Hiragana’s Indian origins are apparent. Not only do the ordering of hiragana characters resemble the ordering of Devanagari characters (more on that later), but even today Siddham is still used by Japanese Shingon priests to write their Sanskrit mantras.
In fact, the Iroha, a well-known Shingon Buddhist poem (also attributed to Kukai), is a perfect2 hiragana pangram, one that doesn’t re-use any characters:
Iroha
| いろ は にほへと | Iro ha nihoheto | Even the blossoming flowers |
| ちりぬる を | Chirinuru wo | Will eventually scatter |
| わ か よ たれ そ | Wa ka yo tare so | Who in our world |
| つね ならむ | Tsune naramu | Is unchanging? |
| うゐ の おくやま | Uwi no okuyama | The deep mountains of karma— |
| けふ こえて | Kefu koete | We cross them today |
| あさき ゆめ みし | Asaki yume mishi | And we shall not have superficial dreams |
| ゑひ も せす | Wehi mo sesu | Nor be deluded. |
An alternative English translation is also worth a read (reproduced here):
Although its scent still lingers on
the form of a flower has scattered away
For whom will the glory
of this world remain unchanged?
Arriving today at the yonder side
of the deep mountains of evanescent existence
We shall never allow ourselves to drift away
intoxicated, in the world of shallow dreams.
Hiragana Pangram
While the Iroha is a lovely pangram, it’s a bit dated. Some of the characters, like ゐ and ゑ, have dropped out of use. Others, like む, have changed their pronunciation. A more modern pangram (though it still contains some obsolete characters) is below:
とりなくこゑす ゆめさませ みよあけわたる ひんかしを そらいろはえて おきつへに ほふねむれゐぬ もやのうち
This pangram is pronounced “torinakukowesu yumesamase miyoakewataru hinkashiwo sorairohaete okitsuheni hofunemurewinu moyanōchi” and means “Awaken from dreaming to the voice of the crying bird and see the coming daylight turning the east sky-blue; shrouded in mist is a flock of ships on the open sea.” (Source)
Kukai’s Second Dream
Kukai’s dream led him to learn the Siddham abugida. But Kukai had another dream - a dream about a simple phonetic script to write Japanese: one based on the holy alphabet of Buddhism. However, things didn’t work out the way Kukai intended. The creation of kana only added to the confusion. While Hiragana might be one of the easiest syllabaries to learn, this is just the tip of the iceberg when it comes to writing Japanese. Not only does Japanese have another parallel syllabary (katakana), but Japanese also uses thousands of Chinese logograms. These logograms have multiple written forms and come packaged with complex rules governing their pronunciation. Kukai’s first dream - to spread Buddhist teachings to Japan - has been largely successful. But his second dream - a simple script for Japanese - has turned into a nightmare.
Abjad: Arabic (العربية)
When the ancient Phonecians sat down and invented their writing system, they ignored the vowels. Like Arabic, Phonecian was a Semetic language; and like Arabic, it had a paucity of vowels: only five or so. Luckily, it’s pretty easy to infer what the vowels are given the context. Even a language like English - which has lots of vowels - cn stll b undrstd f yu wrt t wth nly cnsnnts.

Phonecian died out, but its writing system lived on. The Greeks borrowed it. Finding that it didn’t work with with their more vowel-y language, they modified it by adding seperate vowel symbols, inventing the world’s first alphabet in the process. Interestingly, the alphabet has only been invented once - every single alphabet that has ever existed is ultimately descended from Greek. When other writing systems have been independently invented, they’ve almost always been syllabaries (like Japanese kana). One of these was invented millenia after Greek, in the United States…
The Invention of the Word
In the early nineteenth century, Sequoyah invented a new writing system. A member of the Cherokee people, he voluntarily migrated West to Alabama a decade before the Trail of Tears, the forced relocation of Native Americans to the American West and their ethnic cleansing. In his new home in Alabama, Sequoyah was exposed to a limited fraction of White American culture - he was a blacksmith and leader among his people, but spoke no English and was not a Christian. However, at some point he realized that white people were able to communicate by leaving marks on paper - Sequoyah was inspired to create a script of his own.
After initially experimenting with a logographic system where each mark represented an individual word, he realized that this system would be untenable. Eventually he settled on a syllabary: in his system, each symbol was to represent a different Cherokee syllable (with hacks like in Japanese). It’s clear that this writing system was inspired by English: the glyphs look very similar. However, the sounds have no relationship to English at all. This means that Sequoyah was likely able to look at English writing and the idea clicked without the need for any formal instruction - after all, if he had been instructed, there would probably be some correspondence between Cherokee symbols and their Latin look-alikes - but there isn’t.
Sequoyah was a rare genius - most writing systems don’t have an individual inventor: they evolve over time from other scripts. However, there are a few other inspired scripts: Pawah Hmong was invented by the messianic leader Shong Lue Yang, though he was killed by communist forces during the Laotian Civil War before the writing system could really catch on. The Kikakui script used to write Mande was invented by Mohammed Turay in the late 19th century. Interestingly, the world’s inspired scripts are all syllabaries or abugidas, implying that there’s something more natural about writing syllables than individual speech sounds (alphabets).

Now let’s turn back to Arabic…
The Logic of Arabic
The Arabs didn’t invent their own writing system: they borrowed it from the Phonecians. Luckily, their language was closely related to Phonecian, so they didn’t have to radically modify the logic of the writing system. However, over time their written language morphed into an elegant shorthand where letters change form based on their location in a word (like Korean). However, the changes that Arabic letters undergo are much more dramatic than Korean. Every Arabic letter has an isolated, initial, medial, and final form (although sometimes these forms are the same), and the letters that make up a word are connected together in a continuous line (though there are some interrupting letters that break the flow). For instance, the letter k can appear four ways: ك = isolated, كـ = initial, ـكـ = medial, and ـك = final (reminder: Arabic is written from right to left).
Arabic isn’t as complicated as it might seem at first: the four forms that a letter can take look mostly the same. Plus, there are some tricks for filling in the missing vowels. One trick is that the letters ي, /j/ and و /w/ often indicate the presence of vowels: ي is /i/ and و is /u/ . Plus, you can use diacritics above or below each Arabic letter to indicate the vowel. Because Muslims value an accurate pronunciation of their holy text, Koranic verses are always written with these disambiguating marks.

Additionally, the vowel-ambiguity of the Arabic writing system matches the grammar of Arabic itself. Most Arabic words are derived from tri-consonantal roots. For instance, the root k-t-b relates to writing: kitaab (كتاب) is “book”, kaatib (كاتب) is “writer”, katabat (كتبة) means “clerks”, etc. So in some sense, vowels are secondary to consonants in Arabic: the roots are where all the “meaning” exists, and the vowels mutate slightly to give you different words, but the essence of a word is always somehow derived from the root.
Because Arabic letters connect together with lines, you can extend the lengths of words to fill blank space on a page, like how you might change the spacing between English words to get nice “blocks” of paragraphs: كتاب can become كــــتــــــاب. This flexibility has allowed for endless artistic experimentation in Arabic caligraphy. Ottoman Sultans used caligraphic representations of their names on official documents (called tughra):

However, Arabic isn’t without its drawbacks. Because of its cursive nature, Arabic isn’t easy to print with a machine. Europeans began printing books in the late fifteen century, but it took a few hundred years longer for the first books to be printed in the Arabic writing system: even though by many measurements the Ottoman Empire was far ahead of the Western world in cultural development. Eventually as the Ottoman Empire collapsed and turked into Turkey, the Arabic writing system was rejected and replaced with Latin during Ataturk’s rush to “modernize” the country. Turkish is not a Semitic language, and the Arabic writing system wasn’t considered essential. In the present day, all the Turkic languages are written with the Latin or Cyrillic alphabets (except Uyghur).
More Borrowings
Like the Arabs, the Mongolians were in need of a writing system. Instead of inventing their own, they borrowed one. The Syriac alphabet is closely related to Arabic, and Syriac was the language of choice for the Nestorian Christian church. The wife of Genghis Khan and many other early leaders of the Mongolian Empire were Christians. The branch of Christianity that had penetrated into Asia was the Nestorian Church, so when priests began introducing writing to the nomadic empire, they used their own script. However, their version of the syriac writing system was flipped ninety degrees - making its overall appearance match the column structure that Chinese is written in.
When the Dunhuang manuscripts were uncovered, many were written in this top-to-bottom script (technically Sogdian, the ancestor to the Mongol Empire’s writing system).

An Arabic Pangram
The mutability of its characters makes finding satisfying pangrams in Arabic a bit difficult. Should we go the way of English, and simply ignore some letter forms and prioritize others? Or should we try to hack together a pangram that uses every form its letters take?
نص حكيم له سر قاطع وذو شأن عظيم مكتوب على ثوب أخضر ومغلف بجلد أزرق
This is pronounced “naṣun ḥakymun lahu syrun qāṭiʿun wa ḏu šānin ʿẓymin maktubun ʿala ṯubin aẖḍra wa muġalafun biǧildin azraq” and means “A wise text which has an absolute secret and great importance, written on a green tissue and covered with blue leather.”
I haven’t found a pangram that will solve the multiple-forms problem. However, things get even trickier with the next two writing systems:
Abugida: Devanagari (देवनागरी)

Devanagari has a similar logic to Arabic. However, instead of writing consonants without vowels, you write consonants with obligatory vowels. Devanagari characters are written independently before being connected with a vertical line that runs along their tops. Most characters connect to their neighbors; however, like in Arabic, there are a few interrupting characters. Because Devanagari is difficult to form pangrams in (more on that later!), I’ve provided an acrostic word-list to assist learning. Examples of the primary 61 Devanagari characters are shown below:
An Almost Acrostic
Note: I’ve used my own variation of the standard Hunterian transliteration. I’ve used double vowels (aa) instead of overlines (ā) to represent long vowels.
| Character | IPA | Example | Pronunciation | Meaning |
|---|---|---|---|---|
| क | k | काली | kaalee | black |
| ख | kʰ | खेल | khel | game |
| ग | g | गाय | gaay | cow |
| घ | ɡʱ | घास | ghaas | grass |
| ङ * | ŋ | |||
| च | tʃ | चावल | chaaval | rice |
| छ | tʃʰ | छह | chay | six |
| ज | dʒ | जूता | joota | shoe |
| झ | dʒʱ | झील | jheel | lake |
| ञ * | ɲ | |||
| ट | ʈ | टांग | taang | leg |
| ठ | ʈʰ | ठग | thag | cheat |
| ड | ɖ | डेस्क | desk | desk |
| ढ | ɖʱ | ढक्कन | dhakkan | lid |
| ण * | ɳ | बाण | baan | arrow |
| त | t̪ | तलवार | talavaar | sword |
| थ | t̪ʰ | थरमस | tharmas | thermos |
| द | d̪ | दूध | doodh | milk |
| ध | d̪ʱ | धारा | dhaara | stream |
| न | n | नीला | neela | blue |
| प | p | पनीर | paneer | cheese |
| फ | pʰ | फोजी | phojee | soldier |
| ब | b | बैंक | baink | bank |
| भ | bʱ | भूरा | bhoora | brown |
| म | m | महिला | mahila | woman |
| य | j | युवा | yuva | young |
| र | r | रोटी | rotee | bread |
| ल | l | लाल | laal | red |
| व | v, ʋ, w | वाइन | vain | wine |
| श | ʃ | शलजम | shalajam | turnip |
| ष | ʃ, ʂ | षट्भुज | shatbuj | hexagon |
| स | s | सफेद | saphed | white |
| ह | ɦ | हरा | hara | green |
| क़ ** | q | क़िला | qila | fortress |
| ख़ ** | x | ख़ान | khan | Khan |
| ग़ ** | ɣ | आग़ा | aga | Aga |
| ड़ ** | ɽ | खिड़की | khidakee | window |
| ढ़ ** | ɽʱ | पढ़ना | padhana | read |
| फ़ ** | f | फ़ोन | fon | phone |
| ज़ ** | z | ज़ेबरा | zebara | zebra |
| झ़ ** | ʒ | झ़ामबिल | jaambil | Jambyl |
| क्ष † | kʃ, kʂ | क्षर | kshar | Kashar |
| त्र † | t̪r | त्रिनिदाद | trinidaad | Trinidad |
| ज्ञ † | gj | ज्ञानपुर | gyaanpur | Gyanpur |
| श्र † | ʃr | श्रीनगर | shreenagar | Srinagar |
| अ | a | अनार | anaar | pomegranate |
| आ | aː | आदमी | aadamee | man |
| इ | ɪ | इंडिया | indiya | India |
| ई | iː | ईरान | eeraan | Iran |
| उ | ʊ | उदास | udaas | sad |
| ऊ | uː | ऊंट | oont | camel |
| ए | eː | एवोकाडो | evokaado | avocado |
| ऐ | ɛː, æ | ऐनक | ainak | spectacles |
| ओ | oː | ओंठ | onth | lip |
| औ | ɔː | औषधि | aushadee | medicine |
| अं | ŋ or m | अंगूर | angoor | grape |
| अः †† | h | |||
| ऋ | ṛ | ऋषि | rishi | saint |
| ॠ †† | ṝ | |||
| ऍ †† | ɛ | |||
| ऑ | ɒ | ऑस्ट्रेलिया | ostreliya | Australia |
* Typically appears only in magic square.
** Nuqta, used in loanwords.
† Irregular ligature.
†† Does not appear in modern Hindi.
Diacritics
All Devanagari letters have an inherent vowel that can be modified or eliminated by a diacritic. For instance, क (ka) can become कि (ki), कु (ku), का (kaa), etc. Diacritics that change the vowel are called matras. There are nine of them:
| Diacritic | Letter with Diacritic | Pronunciation |
|---|---|---|
| none | स | sa |
| ा | सा | saa |
| ि | सि | si |
| ी | सी | see |
| ु | सु | su |
| ू | सू | soo |
| े | से | se |
| ै | सै | sai |
| ो | सो | so |
| ौ | सौ | saw |
A letter can also be given a final n by the anusvara diacritic. For instance, कुंजी (kunjee, key).
A virama, or killer stroke, can eliminate a vowel. For instance, the Hindi transliteration of the name Chris (क्रिस) has a virama under the ka, making it k. However, the virama is not always used. For instance, the word for purple (बैंगनी, bainganee) has a final letter न (na) that is modified by ी to become नी (nee). But the word for eggplant (बैंगन, baingan) should have a virama below the न – it doesn’t: the virama is implied.
The chandrabindu diacritic (ँ) nasalizes the vowel that it sits on top of.
Devanagari also contains many ligatures. Ligatures are created when two letters sit next to each other in the same syllable. For instance, when ओ (au) gets the chandrabindu diacritic, it becomes 🕉, the om symbol sacred in Hinduism, Buddhism, Sikhism, and Jainism. (A ligature that Westerners might be most familiar with is the German ß, which occurs when two s letters combine, such as in the word Straße - strasse, street.) Ligatures are not always easy to dissolve into their constituent sounds, and often need to be memorized.
Devanagari Pangram
Because of its many diacritics and ligatures, it’s difficult to write a pangram in Devanagari. But that’s okay: the point of creating pangrams is to assist us in understanding writing systems. Luckily, Devanagari has an organizational property that takes it far beyond other writing systems.
The Magic Square
Alphabets like English are organized linearly: there are the ABC’s, Alpha and Omega, the beginning and the end - they’re one-dimensional. The ancient Brahmi script and its descendents, like Devanagari, are organized differently: they’re two-dimensional.
The middle of the Devanagari abugida is arranged into a magic square. Letters are arranged vertically by place of articulation (the first line are gutturals, then palatals, retroflex, dentals, and labials) and horizontally by manner of articulation (alternating from unaspirated to aspirated). This is similar to the organization of the International Phonetic Alphabet, a system invented by linguists in order to accurately transcribe all human speech.
| क | ख | ग | घ | ङ |
| च | छ | ज | झ | ञ |
| ट | ठ | ड | ढ | ण |
| त | थ | द | ध | न |
| प | फ | ब | भ | म |
This clever organization is fundamental to shiksa (phonology), one of the six Vedic studies. The understanding that consonants are more than just series of individual sounds opens up linguistics to a deeper form of inquiry, where the specific relationship between sounds can be discovered. It’s no coincidence that Brahmic abugidas and Indian numerals spread across much of the world: India was far ahead of the rest of humanity in its understanding of linguistics. This organization was so influential that it was even used hundreds of years later as the basis of the constructed Cree Abugida.

Logography: Chinese (漢字)
The earliest writing systems used pictographs. Ancient Sumerian, Egyptian, Mayan, and Chinese all did this: to represent a sun, a scribe would draw a picture of the sun. A bull would be a bull. A flower a flower. Over time writers learned that this system was untenable, and it eventually died out.
One transformation occured when writers began transforming their pictographs into logographs, which are abstract pictographs. Instead of trying to draw a perfect eyeball, you might just draw a box with a circle in it. And for really confusing concepts, you might get extra creative.
A second transformation occured when writers discovered the rebus principle. Pictograms have meanings, but also sounds. The Sumerians wrote their pictograms using reeds that the impressed into clay. This is called cuneiform writing and is a writing technique, not a writing system. (more on that in this great talk). An was the god of the Sky in the Sumerian religion and was written with this sun-like cuneiform character:

The sound of the character 𒀭 could then be used in other words that didn’t have their own symbols. For instance, the Sumerian word for “iron” was anbar, so it was written as 𒀭𒁇 - “an” + “bar”. The rebus principle eventually transformed logogram systems like Sumerian and Egyptian into syllabaries and alphabets. However, one language never moved past the logogram phase: Chinese.
The principle of Chinese logograms is simple: one character for one morpheme (or word). This eliminates all the complicated rules that other writing systems have: rules that govern diacritics, ligatures, allographs, etc. But this is an example of something that is simple in principle but unwieldy in practice. While it might make sense to have an individual character for each word if your language only has a few hundred words, this simply doesn’t scale.
While writing pangrams in Devanagari might be tough, they’re impossible in Chinese. There are many thousands of Chinese logograms: a pangram would have to be as long as a dictionary. The Oxford English dictionary lists 171,476 in English, and we should expect about the same number in Chinese.

Weaving Everything Together
Pangrams give us some hints about which writing systems are easiest to learn. Korean is a simple alphabetic script that lacks annoying allographs (unlike English) and can be learned in just a few hours.
Writing systems like the Japanese kana are a bit more complicated, but have some simple hacks that allow them to represent all the sounds in the language. The Iroha is a pangram poem that captures all of Japanese Hiragana.
Arabic is more challenging to find a satisfying pangram in, as each letter has several allographs. However, these allographs resemble each other, and Arabic is not difficult to learn.
Devanagari, an abugida, has numerous ligatures and diacritics that make it difficult to create pangrams. However, Devanagari has an interesting organizational principle - the magic square - that can be used in language learning.
Chinese logograms are difficult to acquire and must be learned by hundreds of hours of rote memorization. But this writing system is simple in principle and has the same logic of some of the earliest human writing systems.
My Pangram
Here’s my attempt at an English pangram:
“Waxy fish pangrams blaze,” Jake equivocated
I’ll end with that.